
Кластеризация морфологических множеств
Генерируемые на морфологических таблицах морфологические множества вариантов систем имеют сложную неоднородную внутреннюю структуру. Выявление закономерностей строения исследуемых множеств позволяет более эффективно решать основные задачи по поиску, прогнозированию и планированию рациональных систем. Предварительная кластеризация морфологических множеств с учетом особенностей структуры и свойств вариантов систем помогает во многих задачах преодолеть проклятие размерности, отсеять неинтересные для исследователя варианты систем. Можно выделить два способа формирования классов. Первый способ заключается в том, что классы формируются в процессе конкретного исследования. Второй способ предполагает предварительное задание классов исследователем. При проведении исследований, связанных с выявлением новых классов, применяются методы, позволяющие проводить иерархическое упорядочение морфологических множеств на основе мер сходства; определять подмножества вариантов, наиболее сходных между собой по различным признакам и свойствам; выявлять классы, содержащие наиболее типовые или наиболее оригинальные варианты. Если отряды классов задаются предварительно исследователем, то решается задача идентификации. Цель идентификации — распознавание синтезируемого на морфологической таблице варианта системы и отнесение его к тому или иному классу с учетом решающих правил. Таким образом, осуществляется сортировка синтезируемых вариантов по классам.
Результаты кластеризации в конечном итоге определяются способом описания альтернатив в морфологической таблице, правилом вычисления меры сходства, методом построения иерархической классификации, структурой морфологической таблицы, способом задания классов при решении задачи идентификации.
Решая задачи исследования морфологических множеств на основе методов кластерного анализа, следует различать три существенно отличающихся способа описания альтернатив в морфологической таблице. Способ описания альтернатив обусловливает метод вычисления меры сходства между синтезируемыми вариантами систем. Можно выделить три способа описания альтернатив и соответствующие им правила определения сходства между вариантами.
Первый способ описания каждой альтернативы предполагает указание только ее наименования, например описание альтернативы может быть представлено в виде Аij. При втором способе описания каждая альтернатива имеет наименование и экспертные оценки, указывающие степень сходства со всеми другими альтернативами, принадлежащими одной обобщенной функциональной подсистеме. Третий способ представления предусматривает указание для каждой альтернативы классификационных признаков. Указанная для характеристики альтернатив информация используется при вычислении мер сходства между синтезируемыми вариантами. Вычисление мер сходства осуществляется по различным правилам.
При первом способе описания альтернатив в виде наименований Аij меры сходства между двумя вариантами S' и S" вычисляются по известной формуле
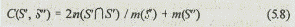
с учетом следующих правил:
• число элементов множества, образующего вариант системы S¢ или S¢¢', равно числу альтернатив Аij, входящих в данное множество;
• число пересечений элементов двух множеств S' и S" равно числу одинаковых пар альтернатив А¢lm и А¢¢lm, принадлежащих соответственно вариантам S' и S", т. е.